

Physicians spend about 60% of their day scribing the EHR (Electronic Health Record) documentation. World Medical Association is calling a “pandemic of physician burnout,” by tedious electronic paperwork to document patient information for insurance coverage, financial reimbursement, and medicolegal liability protection. A 2019 study published in the Annals of Internal Medicine estimated the costs of physician turnover and reduced clinical hours at $4.6 billion per annum.
Introduction
The goal is to develop an algorithm that can extract answers and autofill a clinical report from a physician-patient conversation, which is currently filled by the physician himself. In NLP, the class of problems that deals with such situations is known as Machine Reading Comprehension (MRC) task. In this blog post, we will discuss the various machine comprehension tasks, in particular, the conversational reading comprehension tasks. We will also discuss the domain-specific strong baselines that one can build without labeled data in that domain.
Thanks to the recent advancements in NLP and Transfer Learning, a powerful pre-trained model such as BERT (a bidirectional transformer) can perform Few-shot/ Zero-shot learning i.e. the ability to perform any task with a few/without labeled from the target domain.

We also explore Zero-shot learning capabilities of BERT and its derivatives for Conversational Machine Comprehension (CMC). The key difference between Machine Reading Comprehension (MRC) and CMC is adapting to multi-turn dialogues by understanding the context.
In datasets with single-turn questions, BERT performs exceptionally well on answer span prediction. But this task is limited to BERT accepting only two segments in one input sequence, i.e. one question and one paragraph! A CMC task is dealing with multi-turn questions that reference one paragraph multiple times.
Trending Chatbot Articles:
1. Top 5 Music Bots for Discord and Telegram
2. GUIDE: How to Create a (damn cool) Multi-Language Chatbot with Manychat
3. A Powerful Chatbot CMS Solution for Conversational Chatbots
4. Platforms, NLP Systems, and Courses for Voice Bots and Chatbots
“In 2002, Musk founded SpaceX, an aerospace manufacturer, and space transport services Company, of which he is CEO and lead designer.”
Single-turn questions (e.g. SQuAD, WikiQA, SelQA, InfoQA datasets):
- Q: Who is mentioned in the text? A: Musk;
- Q: Which company did Musk work for? A: SpaceX;
- Q: When did Musk join SpaceX? A: 2002;
- Q: What was Musk’s position in SpaceX? A: CEO.
Multi-turn questions (e.g. CoQA, QuAC datasets):
- Q1: Person: Who is mentioned in the text? A: e1.
- Q2 Company: which companies did e1 work for? A: e2
- Q3 Position: what was e1’s position in e2? A: e3
- Q4 Time: During which period did e1 work for e2 as e3 A: e4
A patient-physician conversation is in the form of Question-Answer, we can model it as a “clinical-conversational machine comprehension”.
Challenges:

Model Workflow:

In any language modeling, the context and question are converted to position and token embeddings which are then converted into logits via BERT model.
A CMC task predicts four important labels:
- Start: the start of the input text; the answer in the above example “male” is encoded in the word in 7th position in the context
- End: the end of the input text; the location is the same as above since it is a single word.
- Span_text: The sentence containing the answer; “joey looked ill so she kept him”
- Input_text: The answer; “male”
The test dataset is a recorded patient-physician conversation that is transcribed to text, and 12 pairs of question-answer per conversation. In total there were 10 conversation paragraphs. I convert this dataset to CoQA format.
For modeling a clinical conversation task, I used ALBERT (A lite BERT) and ClinicalBERT to compare the performance.
First step: Fine-tune ALBERT and ClinicalBERT on CoQA dataset.
Note: ALBERT is pre-trained in Wikipedia articles. ClinicalBERT is pre-trained in clinical texts.
Next: Test the trained models on the test dataset and compare results.
Evaluation Metric:
The two metrics widely adopted in Machine comprehension is
- Exact Match
- F1

Results:
Overall, in the test set, ClinicalBERT performs better. This is because ClinicalBERT has been pre-trained in clinical conversations and most of the conversation on the test set was clinical text. But ALBERT is not far behind.

Q1: Does the model predict unanswered questions?
Effect of task-specific fine-tuning:
Even though we did not have physician-patient conversation training data, fine-tuning the model on a public conversational dataset (CoQA) enabled it to understand the context and tie the question to the context to get the correct answer. An example is given below.

Q2: When does ALBERT perform better than ClinicalBERT?
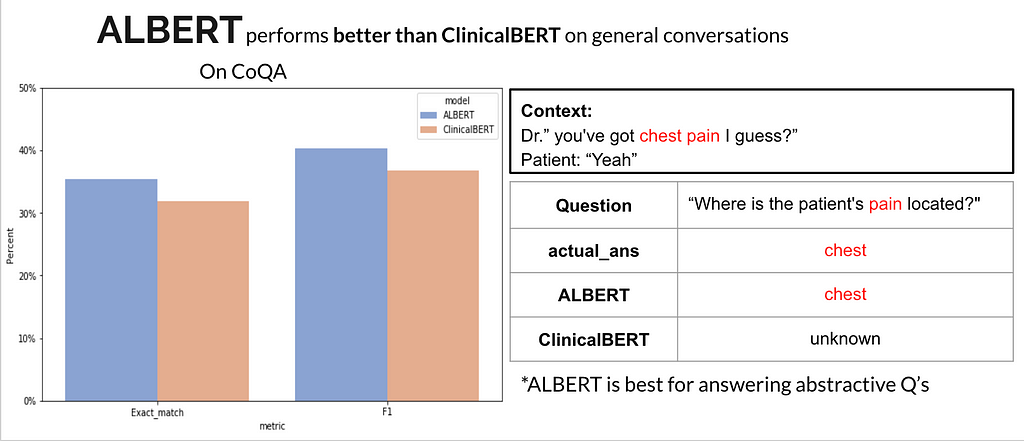
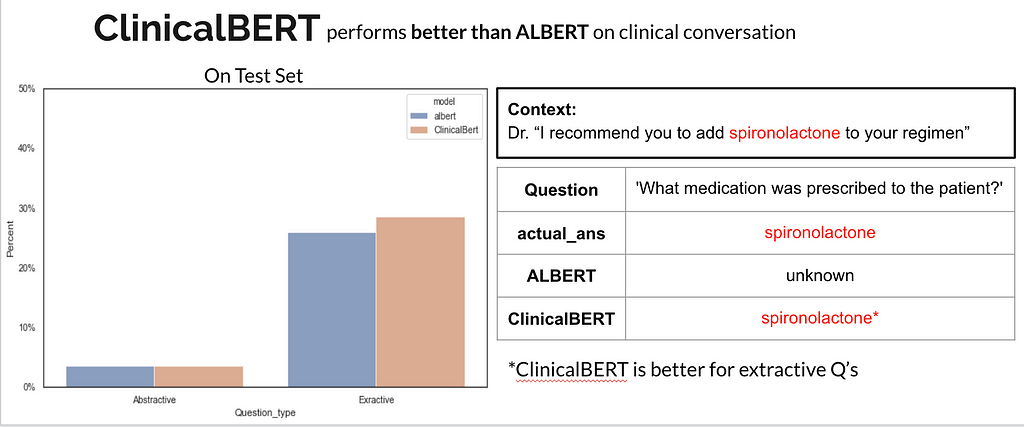
Q3: When does ClinicalBERT perform better than ALBERT?
Effect of pretraining BERT
In the following example, we can observe that ClinicalBERT can recognize medical terms whereas ALBERT is not.
How can we improve?
- Conditional ensembling of the two models, namely ALBERT and ClinicalBERT would improve performance in both general and clinical questions.
- Explore few-shot learning for the same
- Use BERT spell checker before converting the sentences to embeddings.
Want to run the models on your own dataset? The code can be found here! [GitHub]
References
[1] Entity-Relation Extraction as Multi-turn Question Answering https://arxiv.org/pdf/1905.05529.pdf
[2] ALBERT: A Lite BERT for Self-supervised Learning of Language Representations https://arxiv.org/pdf/1909.11942.pdf
[3] Publicly Available Clinical BERT Embeddings https://arxiv.org/pdf/1904.03323.pdf
[4] How AI in the Exam Room Could Reduce Physician Burnout?
Don’t forget to give us your 👏 !




Question Answering on Medical conversation was originally published in Chatbots Life on Medium, where people are continuing the conversation by highlighting and responding to this story.